Meistens, wenn Sie den Zugriff sperren müssen SeekportBot oder andere crawl bots mit einer Website, die Gründe sind einfach. Der Webspider macht zu viele Zugriffe in kurzer Zeit und fordert die Ressourcen des Webservers an, oder er kommt von einer Suchmaschine, bei der Sie nicht möchten, dass Ihre Website indexiert wird.
Es ist sehr vorteilhaft für eine Website, die von c besucht wirdrawIch stieß mit ihm zusammen. Diese Webspider dienen dazu, den Inhalt von Webseiten in Suchmaschinen zu durchsuchen, zu verarbeiten und zu indizieren. Google und Bing verwenden solche crawIch stieß mit ihm zusammen. Es gibt jedoch auch Suchmaschinen, die Roboter verwenden, um Daten von Webseiten zu sammeln. Seekport ist eine dieser Suchmaschinen, die c verwendetrawder SeekportBot ler zum Indizieren von Webseiten. Leider wird es manchmal übermäßig verwendet und erzeugt unnötigen Datenverkehr.
Inhalt
Was ist SeekportBot?
SeekportBot ein web crawler vom Unternehmen entwickelt Seekport, das seinen Sitz in Deutschland hat (aber IPs aus mehreren Ländern verwendet, darunter Finnland). Dieser Bot wird verwendet, um Websites zu crawlen und zu indizieren, damit sie in den Suchergebnissen von Suchmaschinen angezeigt werden können Seekport. Eine nicht funktionierende Suchmaschine, soweit ich das beurteilen kann. Zumindest hat es für mich keine Ergebnisse für irgendeinen Schlüsselsatz zurückgegeben.
SeekportBot Verwenden user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"So blockieren Sie den Zugriff auf SeekportBot oder andere crawIch habe auf eine Website geklickt
Wenn Sie zu dem Schluss gekommen sind, dass dieser Webspider oder ein anderer nicht notwendig ist, um Ihre gesamte Website zu scannen und unnötigen Datenverkehr zum Webserver zu führen, haben Sie mehrere Methoden, mit denen Sie ihren Zugriff blockieren können.
Firewall auf Webserver-Ebene
Sie sind Firewall-Anwendungen open-source die auf Betriebssystemen installiert werden können Linux und kann so konfiguriert werden, dass Datenverkehr basierend auf mehreren Kriterien blockiert wird. IP-Adresse, Standort, Ports, Protokolle oder Benutzeragenten.
APF (Advanced Policy Firewall) ist eine solche Software, mit der Sie unerwünschte Bots auf Serverebene blockieren können.
Da SeekportBot und andere Webspider mehrere IP-Blöcke verwenden, basiert die effektivste Blockierregel auf "user agent". Also, wenn Sie den Zugriff blockieren möchten SeekportBot mittels APF, alles, was Sie tun müssen, ist, sich mit dem Webserver über zu verbinden SSH, und fügen Sie die Filterregel in der Konfigurationsdatei hinzu.
1. Öffnen Sie die Konfigurationsdatei mit nano (oder ein anderer Verlag).
sudo nano /etc/apf/conf.apf2. Suchen Sie nach der Zeile, die mit „IG_TCP_CPORTS“ und fügen Sie am Ende dieser Zeile den Benutzeragenten hinzu, den Sie blockieren möchten, gefolgt von einem Komma. Zum Beispiel, wenn Sie blockieren möchten user agent "SeekportBot“, sollte die Zeile so aussehen:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Speichern Sie die Datei und starten Sie den APF-Dienst neu.
sudo systemctl restart apf.serviceDer Zugriff auf „SeekportBot“ wird gesperrt.
Filter web crawls mit Hilfe von Cloudflare – Zugriff von SeekportBot blockieren
Mit Hilfe von Cloudflare scheint es mir die sicherste und bequemste Methode zu sein, mit der Sie den Zugriff einiger Bots auf eine Website auf verschiedene Arten einschränken können. Die Methode habe ich auch in dem Fall angewendet SeekportBot um den Datenverkehr zu einem Online-Shop zu filtern.
Angenommen, Sie haben die Website bereits zu Cloudflare hinzugefügt und die DNS-Dienste sind aktiviert (d. h. der Datenverkehr zur Website läuft über Cloudflare), führen Sie die folgenden Schritte aus:
1. Öffnen Sie Ihr Clouflare-Konto und gehen Sie zu der Website, für die Sie den Zugriff einschränken möchten.
2. Gehen Sie zu: Security → WAF und füge eine neue Regel hinzu. Create rule.
3. Wählen Sie einen Namen für die neue Regel, Field: User Agent - Operator: Contains - Value: SeekportBot (oder anderer Bot-Name) – Choose action: Block - Deploy.
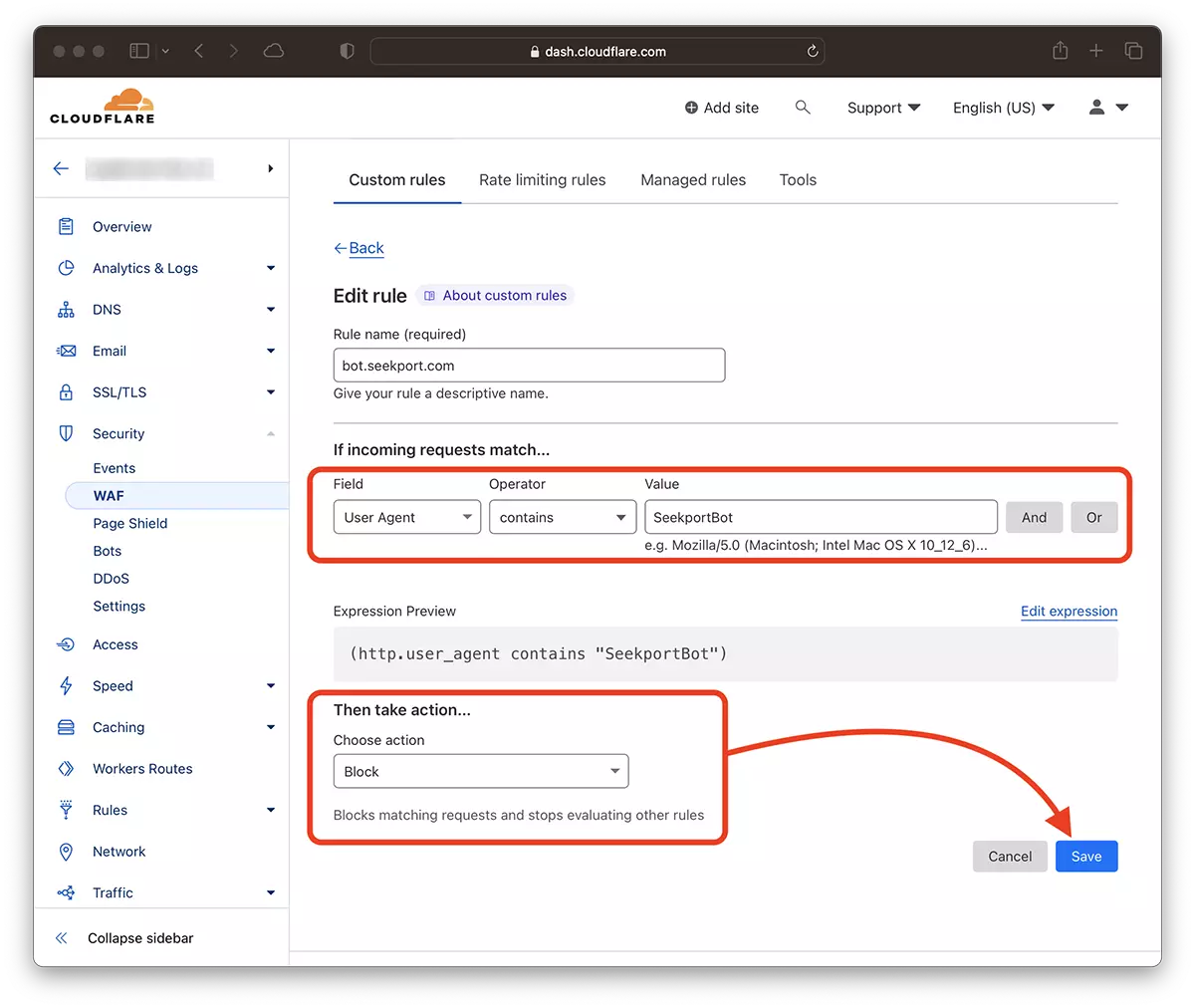
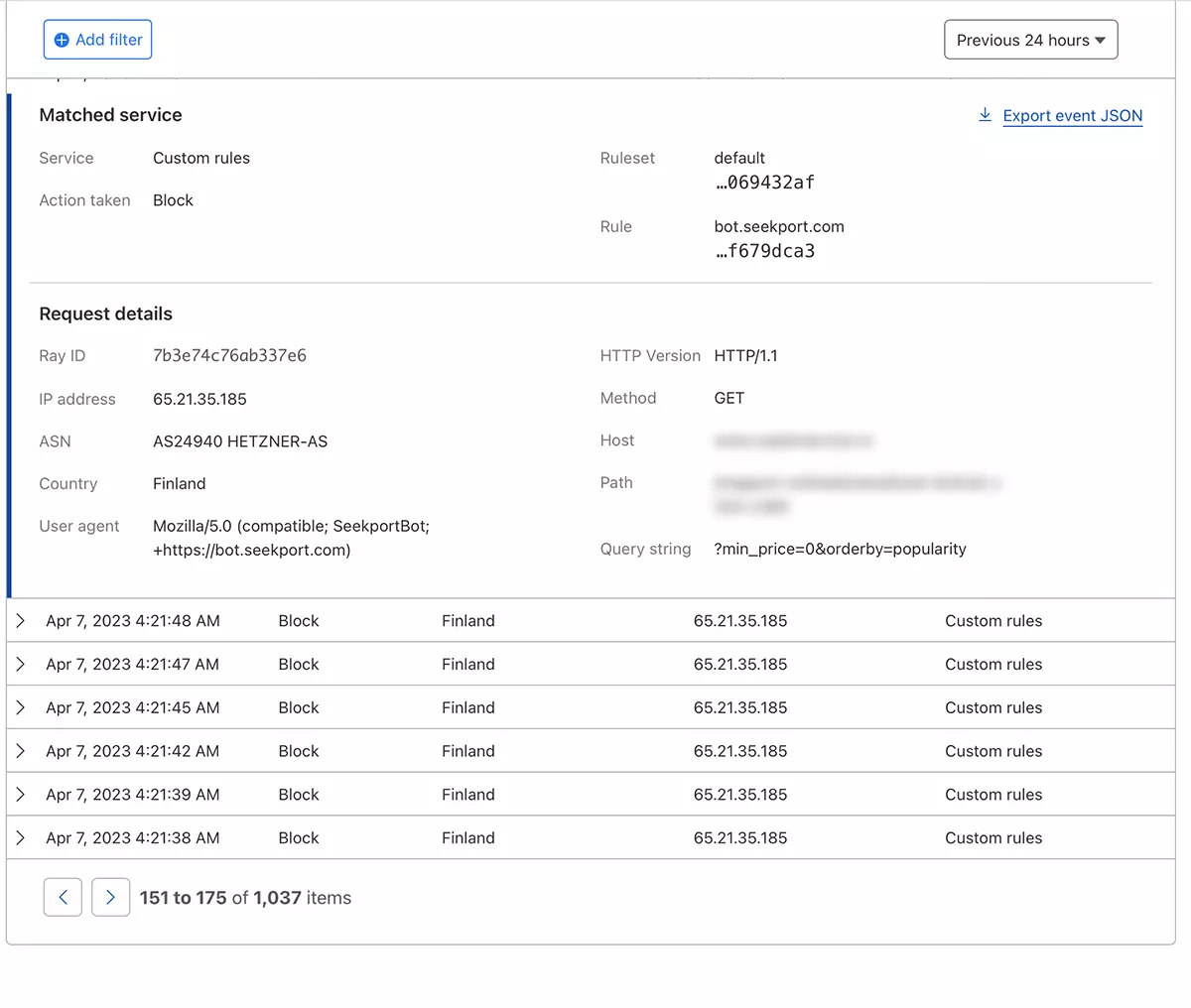
In nur wenigen Sekunden die neue Regel WAF (Web Application Firewall) es beginnt zu wirken.
Theoretisch lässt sich die Häufigkeit einstellen, mit der ein Webspider auf eine Seite zugreift robots.txt, aber ... es ist nur in der Theorie.
User-agent: SeekportBot
Crawl-delay: 4Viele web crawlerii (außer Bing und Google) befolgen diese Regeln nicht.
Abschließend, wenn Sie ein Web identifizieren crawl Wer exzessiv auf Ihre Seite zugreift, sperrt seinen Zugang am besten komplett. Natürlich, wenn dieser Bot nicht von einer Suchmaschine stammt, an der Sie interessiert sind, präsent zu sein.