Automattic, das Unternehmen hinter WordPress und Tumblr, plant Diskussionen, um den Inhalt der Benutzer zu monetarisieren, indem es ihre Daten an KI-Unternehmen wie MidJourney und OpenAI verkauft. Diese Daten von den Blogging-Plattformen Tumblr und WordPress.com werden verwendet, um KI-Modelle zu trainieren.
Obwohl die Einzelheiten der Transaktion noch unklar sind, hat diese Nachricht unter den Benutzern Bedenken hinsichtlich des möglichen Missbrauchs ihrer privaten Inhalte auf den beiden Blogging-Plattformen ausgelöst. Darüber hinaus deutet 404 Media darauf hin, dass es interne Konflikte innerhalb von Automattic gab, da der gesammelte Inhalt private Daten enthält, die nicht für die Aufbewahrung im Unternehmen vorgesehen waren.
Als Reaktion auf die negativen Reaktionen plant Automattic, eine neue Funktion einzuführen, die es Benutzern ermöglicht, ihre Daten nicht für das Training von KI freizugeben. In einem Blogbeitrag bekräftigt das Unternehmen sein Engagement, Tumblr- und WordPress-Benutzern eine größere Kontrolle über ihre Inhalte zu geben. Es erwähnt die Einführung einer Einstellung, um "die Erkundung durch KI-Unternehmen zu entmutigen", und erklärt, dass führende KI-Erkundungsplattformen standardmäßig blockiert sind.
Das Problem der Verwendung von Bloginhalten durch Unternehmen, die KI-Modelle entwickeln, beschränkt sich nicht nur auf von Automattic verwaltete Plattformen. Sowohl OpenAI als auch Google verwenden Webcrawler, um Informationen von allen Websites zu sammeln, um KI-Modelle zu trainieren. Der Prozess ähnelt der Datensammlung durch Suchmaschinen.
Wie können Sie verhindern, dass OpenAI und Gemini (Bard) Daten von Ihrem Blog abrufen?
Wenn Sie einen Blog oder eine Website besitzen und nicht möchten, dass ihre Daten für das Training von KI-Modellen von OpenAI und Gemini verwendet werden, können Sie den Zugriff von Robotern (Crawlern) auf den Inhalt blockieren. Diese Einschränkung kann über die robots.txt-Datei implementiert werden.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
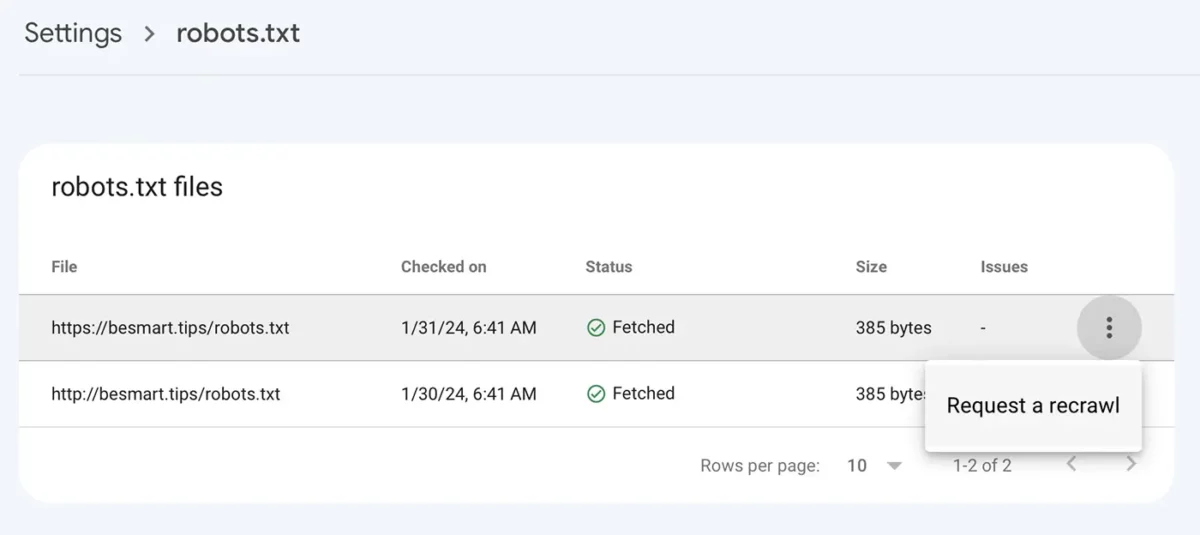
Disallow: /Nachdem Sie die robots.txt-Datei mit den neuen Zeilen gespeichert haben, gehen Sie zu Google Console unter: Einstellungen > robots.txt > klicken Sie auf das Menü mit den drei Punkten, klicken Sie auf "Neue Erkundung anfordern".
Related: GPT-5 und der neue Webcrawler GPTBot, entwickelt von OpenAI.
Für Tumblr- und WordPress-Benutzer kann der Zugriff auf die Datenabruf von Blogs durch OpenAI oder andere Unternehmen, die künstliche Intelligenz entwickeln, über die von Automattic bereitgestellten Tools blockiert werden.